
Was jeder Softwareentwickler 2023 über Unicode wissen muss
2026 – immer noch keine Ausrede!
Ein Artikel von Nikita Prokopov, ins Deutsche übersetzt von Michael Kortstiege.
Vor zwanzig Jahren schrieb Joel Spolsky:
There Ain’t No Such Thing As Plain Text.
It does not make sense to have a string without knowing what encoding it uses. You can no longer stick your head in the sand and pretend that “plain” text is ASCII.
So etwas wie „Plain Text“ gibt es nicht.
Ein String ohne Kenntnis über seine Kodierung ergibt keinen Sinn. Man sollte nicht länger den Kopf in den Sand stecken und so tun, als wäre „Plain Text“ gleich ASCII.
Nach zwanzig Jahren hat sich viel verändert. 2003 war die entscheidende Frage noch: Welches Encoding hat es?
2023 ist das keine Frage mehr: Mit 98%-iger Wahrscheinlichkeit ist es UTF-8. Endlich! Wir können wieder den Kopf in den Sand stecken!
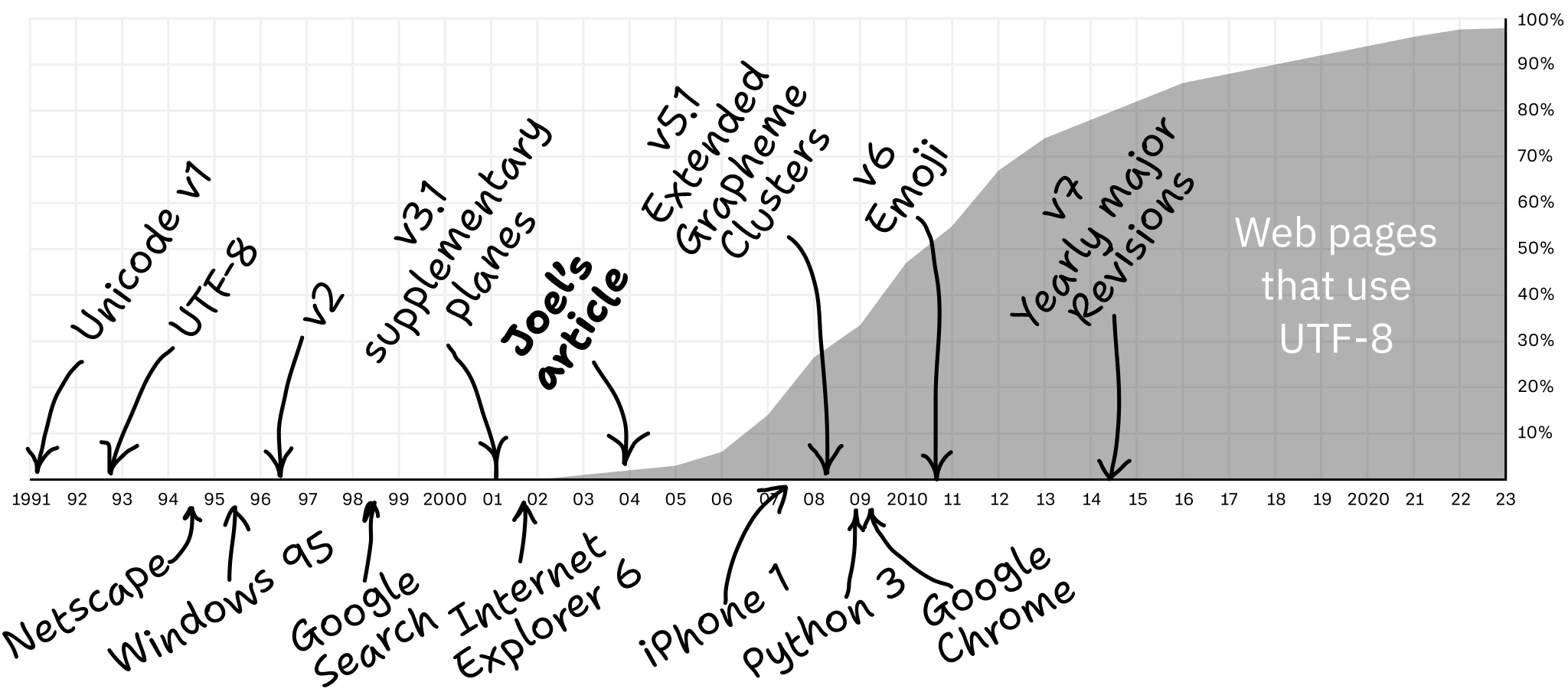
Die Frage heute lautet anders: Wie benutzt man UTF-8 eigentlich richtig? Schauen wir es uns an.
Was ist Unicode?
Unicode ist ein Standard, der darauf abzielt, alle menschlichen Sprachen – vergangene wie gegenwärtige – zu vereinheitlichen und computertauglich zu machen.
Praktisch ist Unicode eine Tabelle, die unterschiedlichen Zeichen eindeutige Zahlen zuweist.
Zum Beispiel:
- Dem lateinischen Buchstaben
Aist die Zahl65zugewiesen. - Dem arabischen Buchstaben Seen
سdie1587. - Dem Katakana-Zeichen Tu
ツdie12484. - Dem Notensymbol Violinschlüssel (G Clef)
𝄞die119070. 💩ist128169.
Diese Zahlen bezeichnet Unicode als Code Points.
Da sich die ganze Welt darauf geeinigt hat, welche Zahlen welchen Zeichen (Characters) entsprechen und wir alle uns darauf verständigt haben, Unicode zu verwenden, können wir somit die Texte der anderen lesen.
Unicode == Zeichen (Character) ⟷ Code Point.
Wie groß ist Unicode?
Der aktuell höchste definierte Code Point ist 0x10FFFF. Das ergibt einen Raum von rund 1,1 Millionen Code Points.
Etwa 170.000 – also 15 % davon – sind derzeit definiert. Weitere 11 % sind für die private Verwendung reserviert. Der Rest, rund 800.000 Code Points, sind momentan nicht vergeben; sie könnten in Zukunft zu Zeichen werden.
So sieht das grob aus:
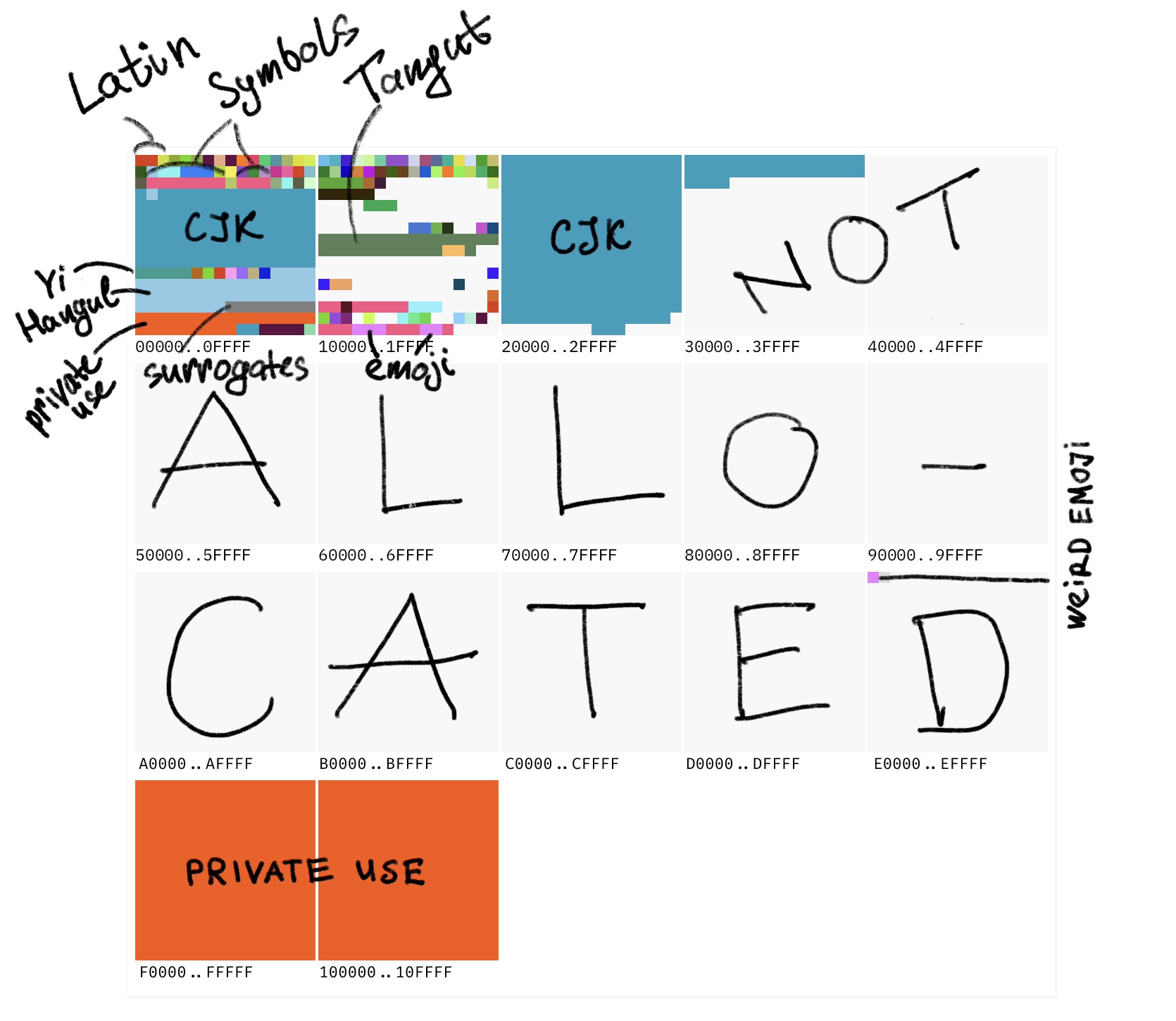
Großes Quadrat == Plane == 65.536 Zeichen. Kleines == 256 Zeichen. Der gesamte ASCII-Zeichenvorrat macht die Hälfte des kleinen roten Quadrats in der oberen linken Ecke aus.
Was sind Private-Use-Zeichen?
Das sind Code Points, die für App-Entwickler reserviert sind und niemals von Unicode selbst definiert werden.
Das Apple-Logo zum Beispiel hat in Unicode keinen Platz. Apple legt es deshalb bei U+F8FF
ab – innerhalb des Private-Use-Blocks. In jeder anderen Schrift erscheint es als fehlendes Zeichen
, aber in Schriften, die mit macOS mitgeliefert werden, sieht man stattdessen folgendes:
Der Private-Use-Bereich wird vor allem von Icon-Fonts genutzt:
Was bedeutet U+1F4A9?
Das ist die Konvention zum Schreiben von Code-Point-Werten. Das Präfix U+ steht für – Wer hätte es gedacht? – Unicode, und 1F4A9 ist die Code-Point-Nummer als Hexadezimalwert.
Oh, und U+1F4A9 ist konkret: 💩.
Was ist dann UTF-8?
UTF-8 ist eine Kodierung. Eine Kodierung legt fest, wie Code Points im Speicher abgelegt werden.
Die einfachstmögliche Kodierung für Unicode ist UTF-32: Code Points werden schlicht als 32-Bit-Integer
gespeichert.
U+1F4A9 wird so zu 00 01 F4 A9
– vier Bytes. Jeder andere Code Point in UTF-32 belegt ebenfalls vier Bytes. Da der höchste definierte Code
Point
U+10FFFF ist, passt garantiert jeder Code Point da rein.
UTF-16 und UTF-8 sind weniger geradlinig, verfolgen aber dasselbe Ziel: einen Code Point als Bytes speichern.
Encoding ist das, womit Programmierer im Alltag tatsächlich zu tun haben.
Wie viele Bytes sind es in UTF-8?
UTF-8 ist eine Kodierung variabler Länge (variable-length encoding). Ein Code Point kann als Folge von ein bis vier Bytes kodiert werden.
Und so funktioniert das:
| Code Point | Byte 1 | Byte 2 | Byte 3 | Byte 4 |
|---|---|---|---|---|
U+[0000..007F] |
0xxxxxxx |
|||
U+[0080..07FF] |
110xxxxx |
10xxxxxx |
||
U+[0800..FFFF] |
1110xxxx |
10xxxxxx |
10xxxxxx |
|
U+[10000..10FFFF] |
11110xxx |
10xxxxxx |
10xxxxxx |
10xxxxxx |
Gleicht man das mit der Unicode-Tabelle ab, erkennt man: Englisch wird mit einem Byte kodiert, Kyrillisch, romanische Sprachen Europas, Hebräisch und Arabisch brauchen zwei, und Chinesisch, Japanisch, Koreanisch sowie andere asiatische Sprachen und Emoji benötigen drei oder vier Bytes.
Ein paar wichtige Punkte:
Erstens
ist UTF-8 byte-kompatibel mit ASCII. Die Code Points 0–127, das ehemalige ASCII, werden mit je einem Byte
kodiert – und zwar exakt demselben Byte.
U+0041 ( A, Lateinischer Großbuchstabe A) ist einfach 41, ein Byte.
Jeder reine ASCII-Text ist auch ein gültiger UTF-8-Text, und jeder UTF-8-Text, der ausschließlich die Codepunkte 0 bis 127 verwendet, kann direkt als ASCII gelesen werden.
Zweitens ist UTF-8 platzsparend für einfache lateinische Zeichen. Das war eines der Hauptargumente gegenüber UTF-16. Für technische Zeichenketten wie HTML-Tags oder JSON-Schlüssel ergibt das Sinn – auch wenn es für Zeichensysteme anderer Sprachen eigentlich nicht fair ist.
Auf den Durchschnitt gerechnet ist UTF-8 in der Regel eine ziemlich gute Wahl – selbst für Computer, auf denen Englisch nicht verwendet wird. Und was Englisch selbst angeht, gibt es schlichtweg keinen Vergleich.
Drittens hat UTF-8 Fehlererkennung und -behebung eingebaut. Das Präfix des ersten Bytes sieht immer anders aus als Byte 2–4. So lässt sich jederzeit feststellen, ob man eine vollständige und gültige UTF-8-Sequenz vor sich hat oder ob etwas fehlt – etwa weil man mitten in eine Sequenz gesprungen ist. Man kann sich dann vorwärts oder rückwärts bewegen, solange bis man einen korrekten Sequenzbeginn findet.
Daraus folgen ein paar wichtige Konsequenzen:
- Die Länge eines Strings lässt sich NICHT durch Zählen der Bytes bestimmen.
- Man kann NICHT beliebig in einen String springen und mit dem Lesen anfangen.
- Valide Substrings lassen sich NICHT durch Trennen an beliebigen Byte-Positionen erzeugen – man könnte ein Zeichen „durchschneiden“.
Wer sich nicht daran hält, begegnet irgendwann diesem Kollegen: �
Was ist denn bloß �?
U+FFFD, der Replacement Character
, ist einfach ein weiterer Code Point in der Unicode-Tabelle. Apps und Bibliotheken können es einsetzen, wenn
sie Unicode-Fehler erkennen.
Wenn ein Teil eines Code Points abgeschnitten wurde, kann man nicht viel mit dem Rest machen, außer einen Fehler anzuzeigen. Dafür wird � genutzt.
var bytes = "Аналитика".getBytes("UTF-8");
var partial = Arrays.copyOfRange(bytes, 0, 11);
new String(partial, "UTF-8"); // => "Анал�"Wäre „UTF-32 für alles“ nicht einfacher?
NEIN.
UTF-32 ist prima zum Arbeiten mit Code Points. Wenn jeder Code Point immer 4 Bytes groß ist, gilt: strlen(s) == sizeof(s) / 4, substring(0, 3) == bytes[0, 12] – und so weiter.
Aber: Man möchte gar nicht mit Code Points arbeiten. Ein Code Point ist keine Einheit fürs Schreiben; ein Code Point muss sogar nicht immer ein einzelnes Zeichen sein. Was man wirklich durchlaufen sollte, nennt sich „Extended Grapheme Cluster“ –oder kurz: Grapheme.
Ein Graphem ist die kleinste bedeutungsunterscheidende Einheit in einem bestimmten Schriftsystem. ö ist ein Graphem. é auch. Und 각. Kurz gesagt: Ein Graphem ist das, was ein Mensch als einzelnes Zeichen wahrnimmt.
Das Problem: In Unicode werden manche Grapheme durch mehrere Code Points kodiert!

é zum Beispiel – ein einzelnes Graphem – ist in Unicode kodiert als e (U+0065 Latin Small Letter E) + ´ (U+0301 Combining Acute Accent).
Zwei Code Points!
Es können auch locker mehr als zwei sein:
☹️istU+2639+U+FE0F👨🏭istU+1F468+U+200D+U+1F3ED🚵🏻♀️istU+1F6B5+U+1F3FB+U+200D+U+2640+U+FE0Fy̖̠͍̘͇͗̏̽̎͞istU+0079+U+0316+U+0320+U+034D+U+0318+U+0347+U+0357+U+030F+U+033D+U+030E+U+035E
Eine Obergrenze gibt es so weit ich weiß nicht.
Wichtig: Wir reden hier von Code Points. Selbst in der breitesten Kodierung, UTF-32, braucht 👨🏭
noch immer 3 * 4-Byte-Einheiten (= 12 Bytes insgesamt). Und es muss trotzdem als einzelnes Zeichen behandelt
werden.
Eine hilfreiche Analogie: Unicode selbst (jegliche Art der Kodierung weggelassen) lässt sich als „hat/ist variable Länge“ denken.
Ein Extended Grapheme Cluster ist eine Sequenz von einem oder mehreren Unicode Code Points, die als einzelnes, unteilbares Zeichen behandelt werden muss.
Damit hat man wieder alle Probleme variabler Encodings – diesmal aber auf Code-Point-Ebene: Man darf nie nur einen Teil einer Sequenz nehmen; sie muss immer als Ganzes ausgewählt, kopiert, bearbeitet oder gelöscht werden.
Wer Grapheme Cluster nicht respektiert, erhält Fehler wie diesen:
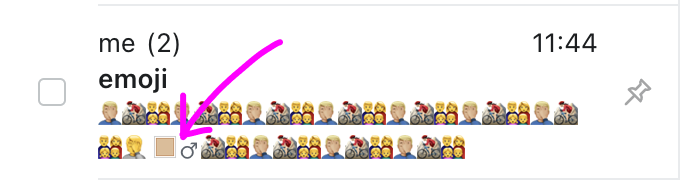
oder diesen:
UTF-32 statt UTF-8 zu verwenden macht das Leben hinsichtlich Extended Grapheme Clusters kein bisschen einfacher. Und Extended Grapheme Clusters sind das, womit man sich wirklich befassen sollte.
Code Points – 🥱. Grapheme – 😍
Liegt das nur an den Emojis?
Nicht wirklich. Extended Grapheme Clusters werden auch in lebenden, aktiv verwendeten Sprachen eingesetzt. Zum Beispiel:
ö(Deutsch) ist ein einzelnes Zeichen, aber zwei Code Points (U+006F U+0308).ą́(Litauisch) istU+00E1 U+0328.각(Koreanisch) istU+1100 U+1161 U+11A8.
Also nein – es dreht sich nicht nur um Emojis.
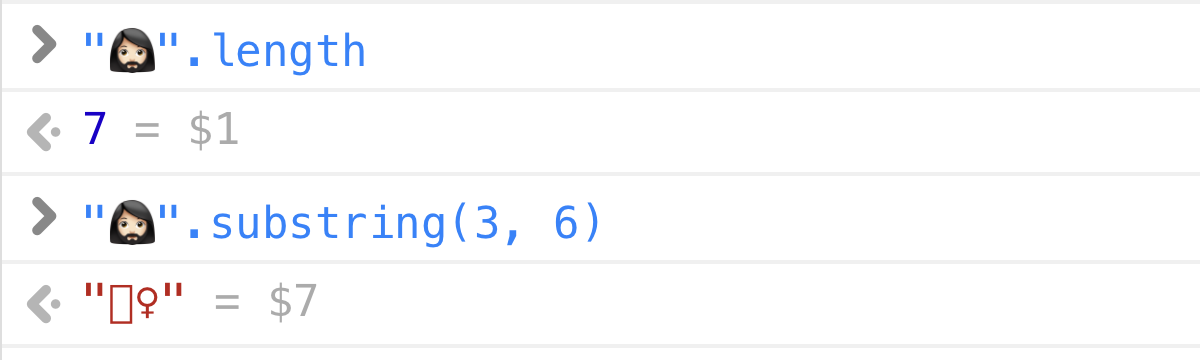
Was ist "🤦🏼♂️".length?
Die Frage ist inspiriert von diesem brillanten Artikel.
Verschiedene Programmiersprachen liefern dir ohne mit der Wimper zu zucken unterschiedliche Ergebnisse.
Python 3:
>>> len("🤦🏼♂️")
5JavaScript / Java / C#:
>> "🤦🏼♂️".length
7Rust:
println!("{}", "🤦🏼♂️".len());
// => 17Der Grund: Verschiedene Sprachen verwenden unterschiedliche interne String-Repräsentationen (UTF-32, UTF-16, UTF-8) und geben die Länge in jeweils unterschiedlichen Einheiten (Ints, Shorts oder Bytes) an.
ABER! Fragt man einen normalen Menschen – einen, der nicht mit dem Wissen über Computer belastet ist – bekommt
man eine klare Antwort: 1. Die Länge von
🤦🏼♂️ ist 1.
Genau darum geht es bei Extended Grapheme Clustern: was Menschen als einzelnes Zeichen wahrnehmen. Und 🤦🏼♂️ ist zweifellos ein einzelnes Zeichen.
Dass 🤦🏼♂️ intern aus 5 Code Points besteht ( U+1F926 U+1F3FB U+200D U+2642 U+FE0F
), ist ein reines Implementierungsdetail. Es sollte nicht aufgetrennt, nicht mehrfach gezählt, nicht
teilweise markiert und der Textcursor nicht darin positioniert werden.
Für alle praktischen Zwecke ist das eine atomare Einheit von Text. Intern kann sie beliebig kodiert sein – für nutzerseitige APIs muss sie als Ganzes behandelt werden.
Die einzigen zwei modernen Sprachen, die das von Haus aus richtig machen, sind Swift:
print("🤦🏼♂️".count)
// => 1und Elixir:
String.length("🤦🏼♂️")
// => 1Im Grunde gibt es zwei Ebenen:
- Intern, computerorientiert: Wie man Strings kopiert, übers Netzwerk sendet, auf Disk speichert etc. Dafür braucht man Encodings wie UTF-8. Swift verwendet intern UTF-8, aber es könnte genauso gut UTF-16 oder UTF-32 sein. Wichtig ist nur, dass man dieses ausschließlich zum Kopieren ganzer Strings nutzt, nie zum Analysieren von deren Inhalt.
-
Extern, nutzerseitig: Zeichenzahl in der UI, erste 10 Zeichen um eine Vorschau zu generieren, Suche in Text,
Methoden wie
.countoder.substring. Swift gibt einem die Sicht darauf , welche vorgibt, der String sei eine Abfolge von Grapheme Clustern. Und die sich dann so verhält, wie es jeder Mensch erwarten würde: Sie liefert 1 für"🤦🏼♂️".count.
Hoffentlich übernehmen bald mehr Sprachen dieses Design.
Frage an den Leser: Was sollte "ẇ͓̞͒͟͡ǫ̠̠̉̏͠͡ͅr̬̺͚̍͛̔͒͢d̠͎̗̳͇͆̋̊͂͐".length deiner Meinung nach ergeben?
Wie erkenne ich denn Extended Grapheme Clusters?
Unglücklicherweise gehen die allermeisten Sprachen den Weg des geringsten Widerstands: sie lassen dich einen einen String in 1/2/4-Byte-Chunks iterieren, aber nicht in Grapheme Clustern .
Das ergibt eigentlich keinen Sinn (und keine Semantik), aber weil es der Standard ist, denken die meisten Entwicklerinnen und Entwickler nicht zweimal darüber nach – und wir sehen kaputte Strings als Ergebnis:
„Ich weiß, ich verwende deshalb einfach eine Bibliothek für strlen()!“ – hat noch niemand gesagt.
Aber genau das sollte man aber tun! Eine echte Unicode-Bibliothek benutzen! Ja, auch für ganz banale Dinge wie
strlen oder indexOf oder substring!
Zum Beispiel:
- C/C++/Java: ICU – eine Bibliothek von Unicode selbst, die alle Regeln zur Textsegmentierung enthält.
- C#:
TextElementEnumeratorverwenden, der nach meinem aktuellem Kenntnisstand mit Unicode aktuell gehalten wird. - Swift: einfach stdlib. Swift macht das Richtige von Haus aus.
- Nachtrag: Erlang/Elixir machen anscheinend ebenfalls das Richtige.
- Für andere Sprachen gibt es wahrscheinlich eine Bibliothek oder ICU-Binding.
- Selbst implementieren: Unicode veröffentlicht Regeln und Tabellen in maschinenlesbarem Format – und alle genannten Bibliotheken basieren darauf.
Worauf man auch setzt: Es sollte eine aktuelle Unicode-Version sein (aktuell 15.1 beim Verfassen dieses
Artikels), denn die Definition von Graphemen ändert sich von Version zu Version. Javas
java.text.BreakIterator
ist z.B. ein echtes „No-Go“: Es basiert auf einer sehr alten Unicode-Version und wird nicht aktualisiert.
Verwende eine Bibliothek.
Das Ganze ist, ehrlich gesagt, eine Schande. Unicode sollte standardmäßig in der Standardbibliothek jeder Sprache enthalten sein. Schließlich ist es die Lingua franca des Internets – und es ist nicht mal neu: Wir leben mit Unicode bereits seit 20 Jahren.
Aber warte, Regeln ändern sich doch?
Ja! Ist das nicht toll?
(Ich weiß, ist es nicht.)
Seit etwa 2014 veröffentlicht Unicode jedes Jahr eine neue Hauptrevision seines Standards. Daher kommen auch die neuen Emojis – Android- und iOS-Updates im Herbst enthalten üblicherweise den neuesten Unicode-Standard.
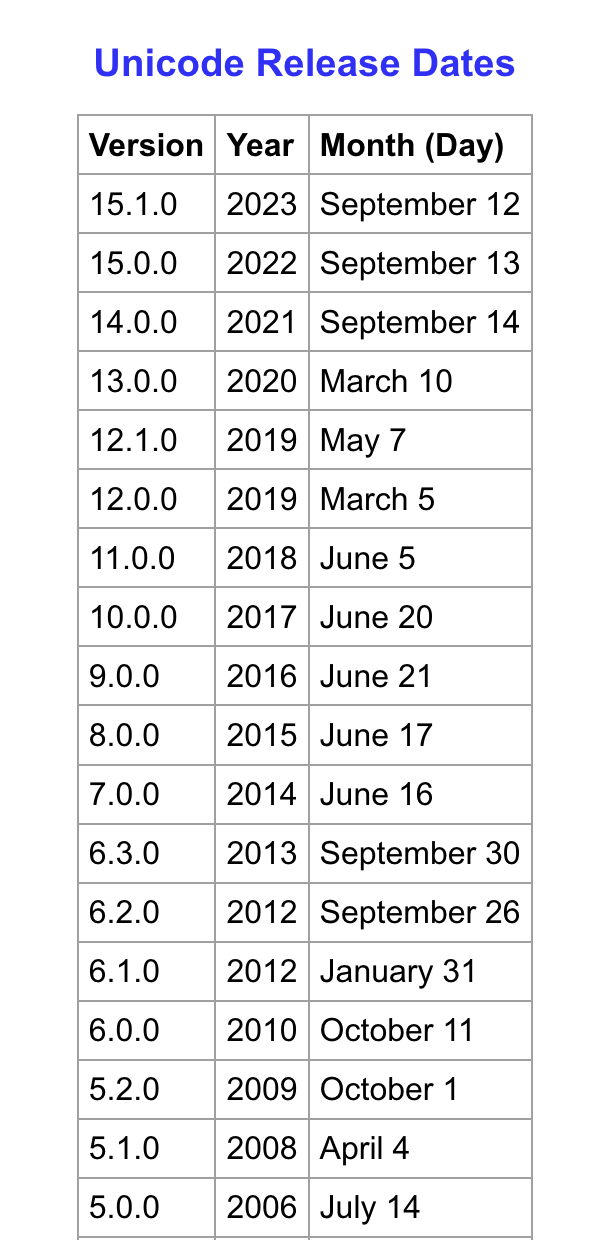
Was für uns unangenehm ist: Die Regeln, die Grapheme Cluster definieren, ändern sich ebenfalls jährlich. Was heute als Folge zweier eigenständiger Code Points gilt, kann morgen ein Grapheme Cluster sein – ohne Vorwarnung, ohne Möglichkeit, sich vorzubereiten.
Noch schlimmer: Verschiedene Versionen deiner eigenen App könnten auf verschiedenen Unicode-Versionen laufen und unterschiedliche Stringlängen melden.
Das ist die Realität. Eine echte Wahl gibt es nicht. Wer relevant bleiben möchte und eine gute Nutzererfahrung bieten will, kann Unicode und seine Updates nicht ignorieren. Also: anschnallen, annehmen, aktualisieren.
Aktualisiere jährlich.
Warum ist "Å" !== "Å" !== "Å"?

Einfach eines davon in die JavaScript-Konsole kopieren:
"Å" === "Å"
"Å" === "Å"
"Å" === "Å"Was kommt raus? False? Richtig – und das ist kein Fehler.
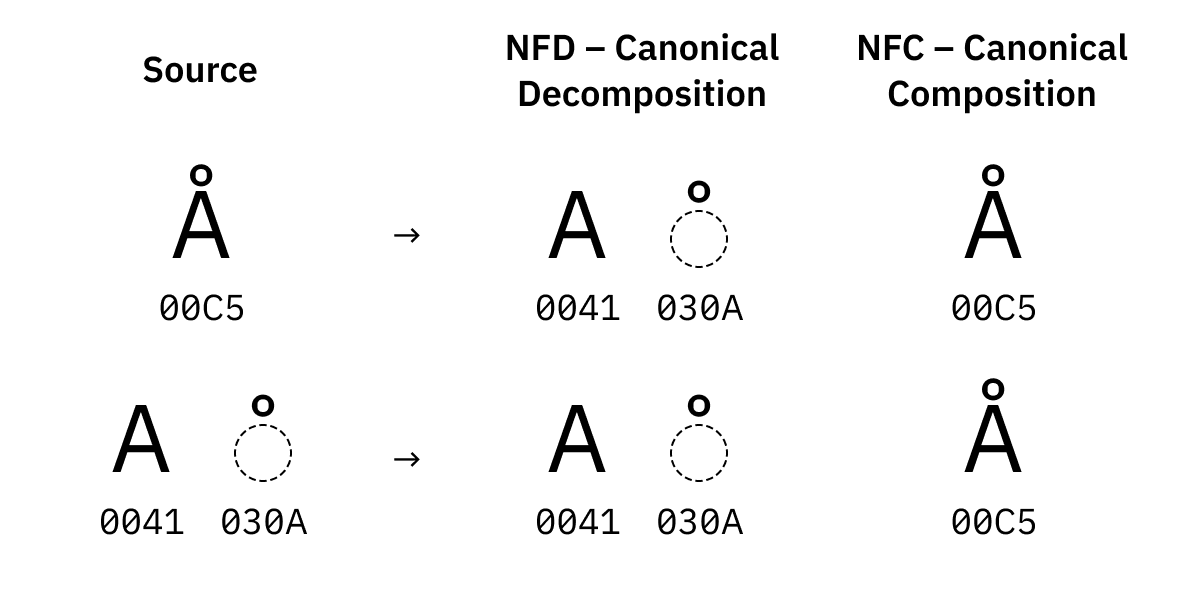
Zur Erinnerung: ö besteht aus zwei Code Points, U+006F U+0308. Unicode bietet generell mehr als einen Weg, Zeichen wie ö oder Å zu schreiben:
Ålässt sich aus einem normalen lateinischenAplus einem Combining Character zusammensetzen,- ODER es gibt einen vorkomponierten Code Point
U+00C5, der das direkt erledigt.
Beide sehen gleich aus ( Å vs Å
), sollten gleich funktionieren und für alle praktischen Zwecke gelten sie als identisch. Der einzige
Unterschied ist die Byte-Darstellung.
Deshalb braucht man Normalisierung. Es gibt vier Formen:
NFD versucht, alles in die kleinstmöglichen Teile zu zerlegen und, falls es mehr als eine Möglichkeit gibt, diese Teile in kanonischer Reihenfolge zu sortieren.
NFC versucht hingegen, alles in eine vorkomponierte Form zusammenzuführen, sofern eine existiert.
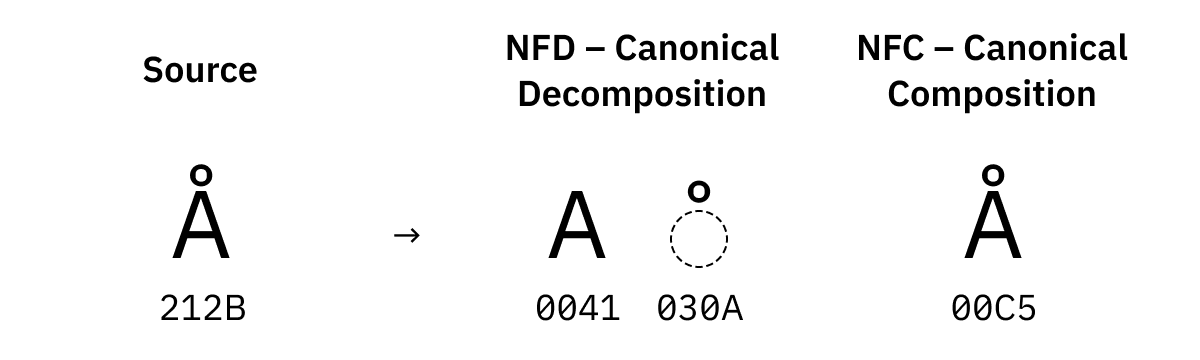
Für manche Zeichen gibt es auch mehrere Versionen in Unicode. Es gibt zum Beispiel U+00C5 Lateinischer Großbuchstabe A mit Ring – aber auch U+212B Ångström-Zeichen, welches gleich aussieht.
Diese werden bei der Normalisierung ebenfalls angeglichen:
NFD und NFC nennt man „kanonische Normalisierung“ (canonical normalization). Daneben gibt es zwei weitere Formen, „Kompatibilitätsnormalisierung“ (compatibility normalization) genannt:
NFKD zerlegt alles und ersetzt visuelle Varianten durch die Standardform.
NFKC kombiniert alles und ersetzt dabei ebenfalls visuelle Varianten durch die Standardform.
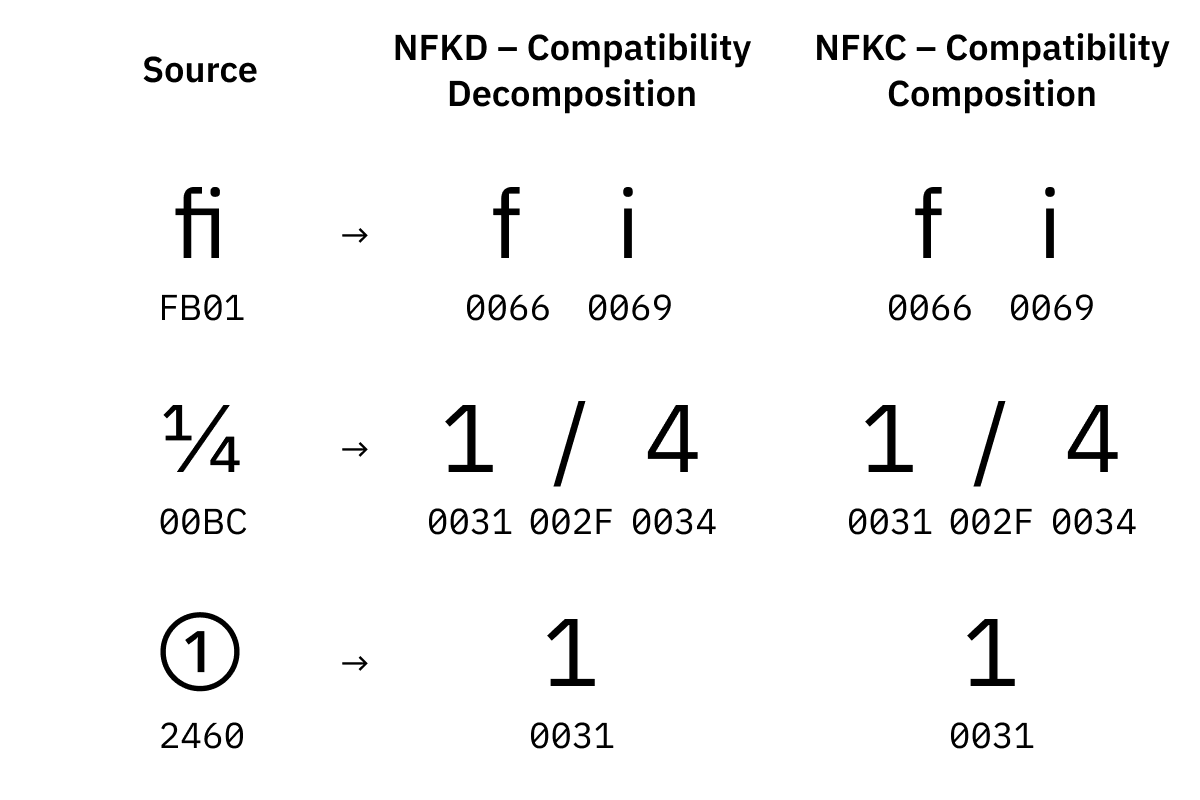
Visuelle Varianten sind separate Code Points, die dasselbe Zeichen repräsentieren, aber anders gerendert
werden sollen – wie
① oder ⁹ oder 𝕏. Man will schließlich sowohl "x" als auch "2" in einem String wie "𝕏²" finden können, nicht wahr?

Warum die fi
-Ligatur einen eigenen Code Point hat? Keine Ahnung. Bei einer Million Zeichen kann viel passieren.
Vor dem Stringvergleich oder der Suche nach Substrings: normalisieren!
Unicode ist locale-abhängig
Der russische Name Nikolay wird so geschrieben:
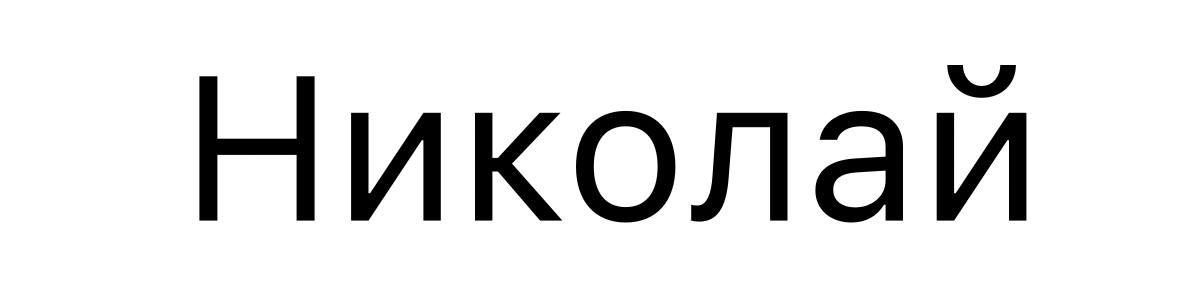
kodiert in Unicode als U+041D 0438 043A 043E 043B 0430 0439.
Der bulgarische Name Nikolay wird so geschrieben:
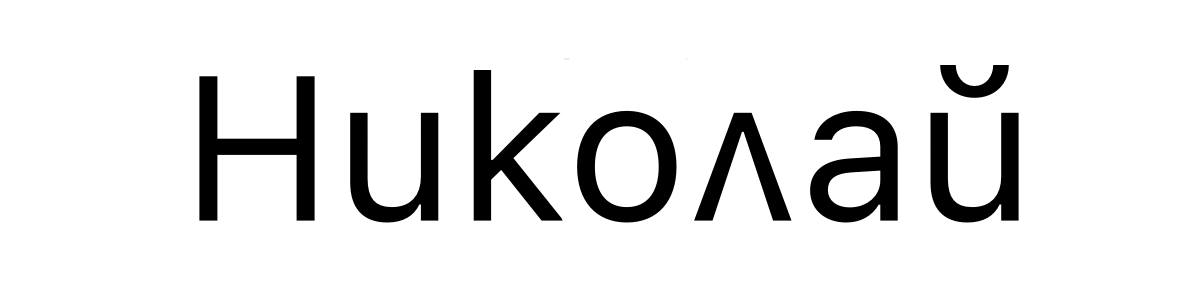
kodiert in Unicode als U+041D 0438 043A 043E 043B 0430 0439. Exakt gleich!
Moment mal – woher weiß der Computer den nun, wann er bulgarische Glyphen rendern soll und wann russische?
Kurze Antwort: Er weiß es nicht. Unicode ist kein perfektes System und hat viele Schwachstellen. Eine davon
ist, dass gleiche Code Points Glyphen zugewiesen werden, die unterschiedlich aussehen – wie kyrillisches k und
bulgarisches „Kleines K“ (beide
U+043A).
Anscheinend trifft das Asiatische Nutzer noch härter : Viele chinesische, japanische und koreanische Logogramme, die sich stark voneinander unterscheiden, erhalten denselben Code Point zugewiesen:

Die Motivation von Unicode dürfte sein, Code-Point-Raum zu sparen (meine Vermutung). Die Information, wie etwas gerendert werden soll, soll außerhalb des Strings transportiert werden, als Locale oder Sprach-Metadaten.
Leider verfehlt das das ursprüngliche Ziel von Unicode:
[…] no escape sequence or control code is required to specify any character in any language.
[…] es darf weder eine Escape-Sequenz noch ein Control Code nötig sein, um ein beliebiges Zeichen in einer beliebigen Sprache zu spezifizieren.
In der Praxis bringt die Abhängigkeit von einer Locale viele Probleme mit sich:
- Als Metadaten gehen Locales häufig verloren.
- Menschen sind nicht auf eine einzige Locale beschränkt. Ich kann Deutsch, Englisch (USA), Englisch (UK) und Russisch lesen und schreiben – auf welche Locale soll ich meinen Computer einstellen?
- Vermischen ist schwierig. Russische Namen in bulgarischem Text oder umgekehrt. Warum nicht? Im Internet begegnen sich Menschen aller Kulturen.
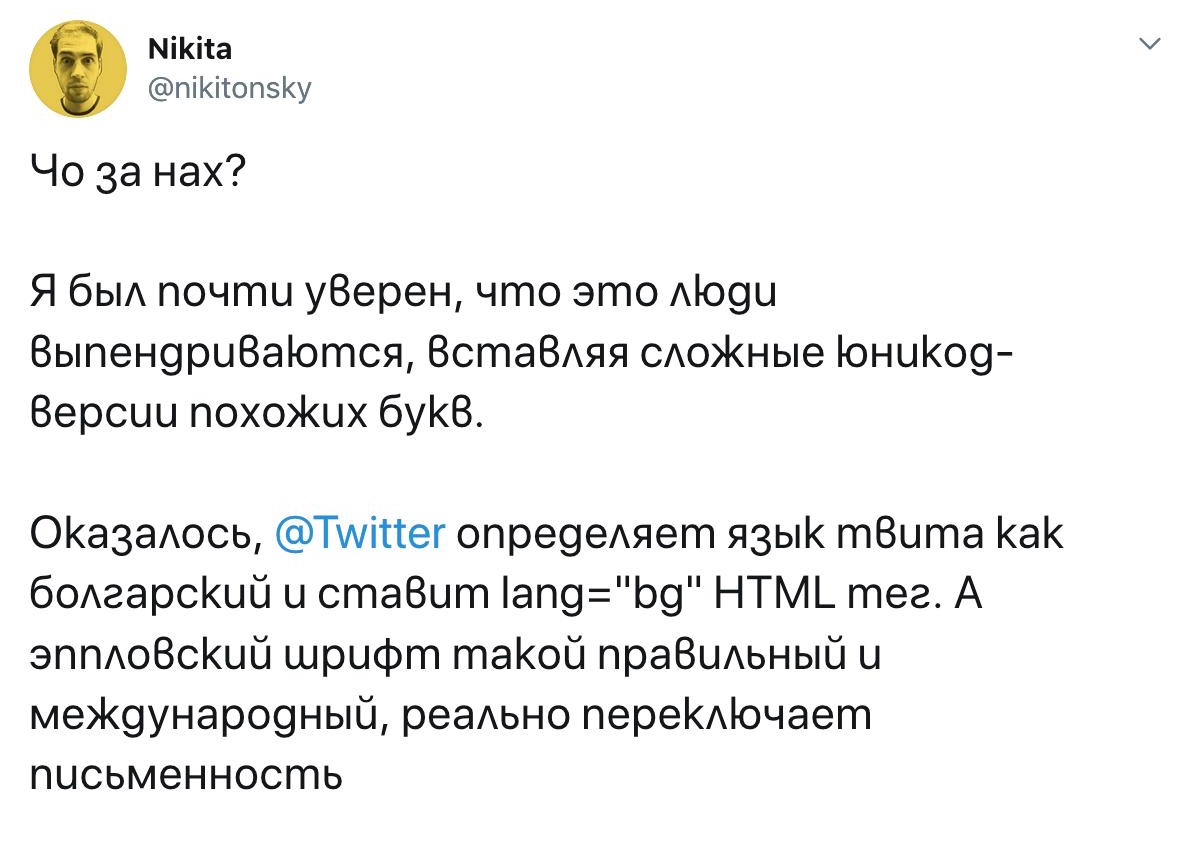
- Es gibt keinen Ort, die Locale anzugeben. Selbst die beiden obigen Screenshots zu erstellen war nicht trivial, weil die meisten Programme kein Dropdown oder Textfeld dafür bieten.
- Falls nötig, muss sie erraten werden. Twitter versucht zum Beispiel, die Locale aus dem Tweet-Text selbst zu erschließen (woher sonst?) und liegt dabei manchmal falsch:
Warum akzeptiert String::toLowerCase() Locale als Argument?
Ein weiteres unglückliches Beispiel für Locale-Abhängigkeit ist der Umgang mit dem punktlosen i im Türkischen.
Anders als im Deutschen oder Englischen gibt es im Türkischen zwei I-Varianten: mit und ohne Punkt. Unicode beschloss, I und i aus ASCII zu übernehmen und nur zwei neue Code Points hinzuzufügen: İ und ı.
Das sorgt dafür, dass toLowerCase/ toUpperCase bei gleicher Eingabe unterschiedliche Ergebnisse liefert:
var en_US = Locale.of("en", "US");
var tr = Locale.of("tr");
"I".toLowerCase(en_US); // => "i"
"I".toLowerCase(tr); // => "ı"
"i".toUpperCase(en_US); // => "I"
"i".toUpperCase(tr); // => "İ"Man kann einen String also nicht in Kleinbuchstaben umwandeln, ohne die Sprache zu kennen, in der er verfasst ist.
Aber ich verwende nur Englisch, warum ist das wichtig für mich?

- typografische Anführungszeichen
“”‘’, - Apostroph
’, - Gedankenstrich und Bindestrich
–—, - verschiedene Leerzeichen (Geviert, Haar, geschützt),
- Aufzählungszeichen
•■☞, - Währungssymbole außer
$(verrät ein bisschen, wer Computer erfunden hat, oder?):€¢£, - mathematische Zeichen – Plus
+und Gleichheitszeichen=sind in ASCII, aber Minus−und Mal×nicht ¯_(ツ)_/¯, - diverse weitere Zeichen
©™¶†§.
Himmel, selbst auf Englisch kann man ohne Unicode weder café noch piñata noch naïve schreiben. Also ja, wir sitzen alle im selben Boot, selbst die Amerikaner.
Touché.
Was sind Surrogate Pairs?
Das reicht zurück bis zu Unicode v1. Die erste Version von Unicode sollte eine feste Breite haben. Genauer gesagt: 16 Bit feste Breite:

Man glaubte damals, 65.536 Zeichen würden für alle menschlichen Sprachen reichen. Fast richtig!
Als klar wurde, dass man mehr Code Points brauchte, war UCS-2, eine frühe Version von UTF-16 ohne Surrogate-Unterstützung, bereits in vielen Systemen im Einsatz. 16 Bit, fixe Breite, maximal 65.536 Zeichen. Was tun?
Unicode beschloss, einen Teil dieser 65.536 Zeichen dafür zu nutzen, höhere Code Points zu kodieren – und verwandelte damit das fixbreite UCS-2 in das variabel breite UTF-16.
Ein Surrogate Pair besteht aus zwei UTF-16-Einheiten, die zusammen einen einzigen Unicode Code Point kodieren.
D83D DCA9 (zwei 16-Bit-Einheiten) kodiert zum Beispiel einen Code Point: U+1F4A9.
Die oberen 6 Bits der Surrogate Pairs sind für die Maske reserviert, die restlichen 2×10 Bits sind frei verwendbar:
High Surrogate Low Surrogate
D800 ++ DC00
1101 10?? ???? ???? ++ 1101 11?? ???? ????
Technisch gesehen können beide Hälften eines Surrogate Pairs auch als Unicode Code Points betrachtet werden.
In der Praxis ist der gesamte Bereich von
U+D800 bis U+DFFF
als „nur für Surrogate Pairs“ reserviert. Code Points aus diesem Bereich gelten in allen anderen Encodings als
ungültig.
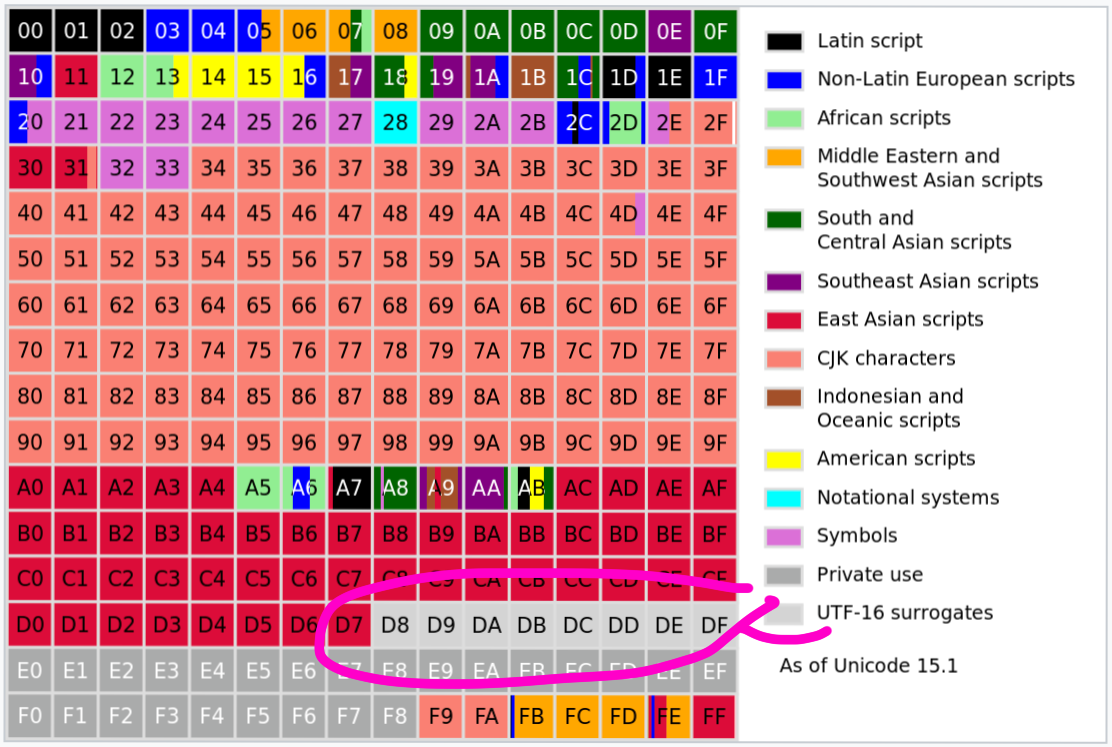
Lebt UTF-16 noch?
Ja!
Das Versprechen eines Encodings in fester Breite für alle menschlichen Sprachen war so verlockend, dass viele Systeme es bereitwillig übernahmen: unter ihnen befanden sich Microsoft Windows, Objective-C, Java, JavaScript, .NET, Python 2, QT, SMS und CD-ROM.
Seitdem hat sich Python weiterentwickelt, die CD-ROM ist Geschichte – aber der Rest steckt bei UTF-16 oder sogar UCS-2 fest. UTF-16 lebt dort als In-Memory-Darstellung weiter.
Praktisch gesehen hat UTF-16 heute in etwa dieselbe Verwendbarkeit wie UTF-8. Es ist ebenfalls „variable-length“; UTF-16-Einheiten zu zählen ist genauso sinnlos wie Bytes oder Code Points zu zählen; Grapheme Cluster sind nach wie vor ein Schmerzpunkt. Der einzige Unterschied liegt im Speicherbedarf.
Der einzige Nachteil von UTF-16: Alles andere ist UTF-8, also braucht es jedes Mal eine Konvertierung, wenn ein String aus dem Netzwerk oder von der Disk kommt.
Ein Fun Fact : Die Anzahl der Unicode-Planes (17) wird genau dadurch definiert, wie viel man mit Surrogate Pairs in UTF-16 ausdrücken kann.
Fazit
Zusammengefasst:
- Unicode hat gewonnen.
- UTF-8 ist das am weitesten verbreitete Encoding für Daten bei Übertragung und Speicherung.
- UTF-16 wird gelegentlich noch als In-Memory-Darstellung verwendet.
- Die zwei wichtigsten Sichtweisen auf Strings: Bytes (Speicher allozieren, kopieren, kodieren, dekodieren) und Extended Grapheme Clusters (alle semantischen Operationen).
- Mit Code Points über einen String zu iterieren ist falsch. Sie sind keine grundlegende Einheit von Schrift. Ein Graphem kann aus mehreren Code Points bestehen.
- Um Graphem-Grenzen zu erkennen, braucht man Unicode-Tabellen.
- Für alles Unicode-bezogene – auch für banale Dinge wie
strlen,indexOfodersubstring– eine Unicode-Bibliothek verwenden. - Unicode wird jedes Jahr aktualisiert; die Regeln ändern sich gelegentlich.
- Unicode-Strings müssen vor dem Vergleichen normalisiert werden.
- Unicode hängt für manche Operationen und beim Rendern von der Locale ab.
- Das alles gilt auch für rein englischen Text.
Insgesamt gilt: Unicode ist nicht perfekt. Aber dass
- eine Kodierung existiert, die alle möglichen Sprachen auf einmal abdeckt,
- sich die ganze Welt darauf geeinigt hat, sie zu verwenden,
- wir Encodings (Kodierungen), Konvertierungen und all das komplett vergessen können
– das ist schon ein kleines Wunder. Unbedingt an alle, die das noch nicht wissen, weiterleiten.
Es gibt so etwas wie „Plain Text“,
und der ist in UTF-8 kodiert.
Thanks Lev Walkin and my patrons for reading early drafts of this article.
Dank an Lev Walkin und meine Unterstützer für das Lesen früher Entwürfe dieses Artikels.